Performance Testing in Cosmos

This is the first post in an upcoming series that dives into the state of performance optimization in the Cosmos blockchain stack. This post will:
- Show how we got up to 1800 transactions per second by doubling down on our testing infrastructure.
- Give insights on our testing methodology and benchmarking workloads.
- Briefly preview the major improvements coming to the Cosmos stack.
Introduction
Last year, our engineering team at Cosmos Labs kicked off a work stream to identify and improve bottlenecks and inefficiencies in the Cosmos stack. Broadly, our mandate was to ensure the stack was both performant and robust enough to support the next generation of financial services being built on top of it via sub-second block times and over 5,000 distributed transactions per second.
Our first priority in this effort was around testing. Cosmos is one of the most established and battle-tested production blockchain frameworks, and we want to ensure it stays that way, so prioritizing testing is already natural to us. We use it to verify the correctness of our algorithms, and we also add more visibility into our baselines via tests. Over the years, there has been a buildup of knowledge around operators and developers of Cosmos chains, but we wanted to reestablish what we knew from empirical data.
For those reasons, we spent a large portion of the first few months of 2025 building testing software, establishing dashboards to capture critical runtime metrics, and running simulations on test networks. It has allowed us to become more confident in the safety of changes we’re making, and it has increased the speed of iteration we can achieve when building prototypes.
If you read the Cosmos Stack roadmap for 2026, you’ll know our current performance goals: 500ms block times, 5,000 transactions per second, and stable performance under load. These reflect what we consider realistic targets based on the results from our live network tests.
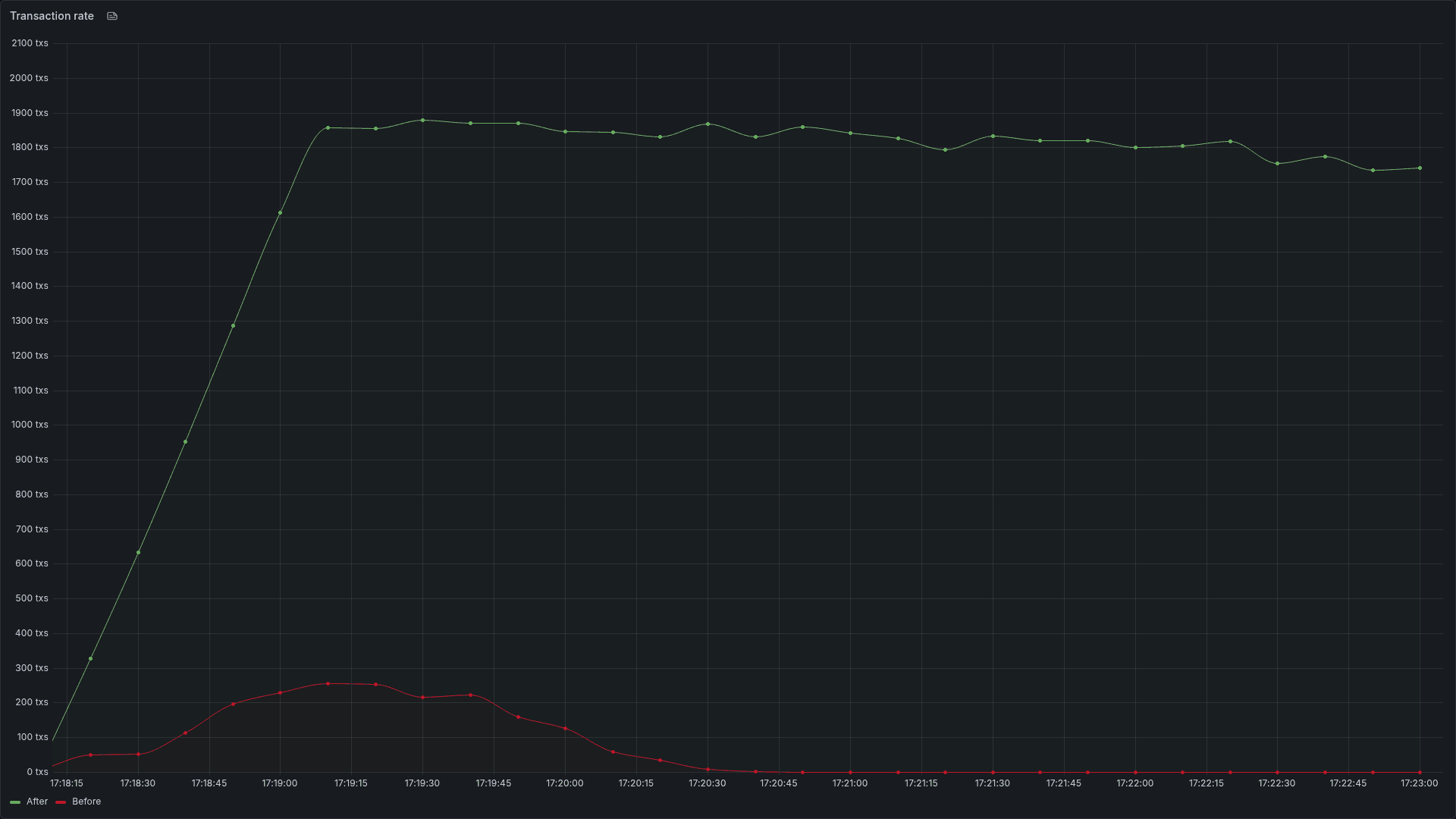
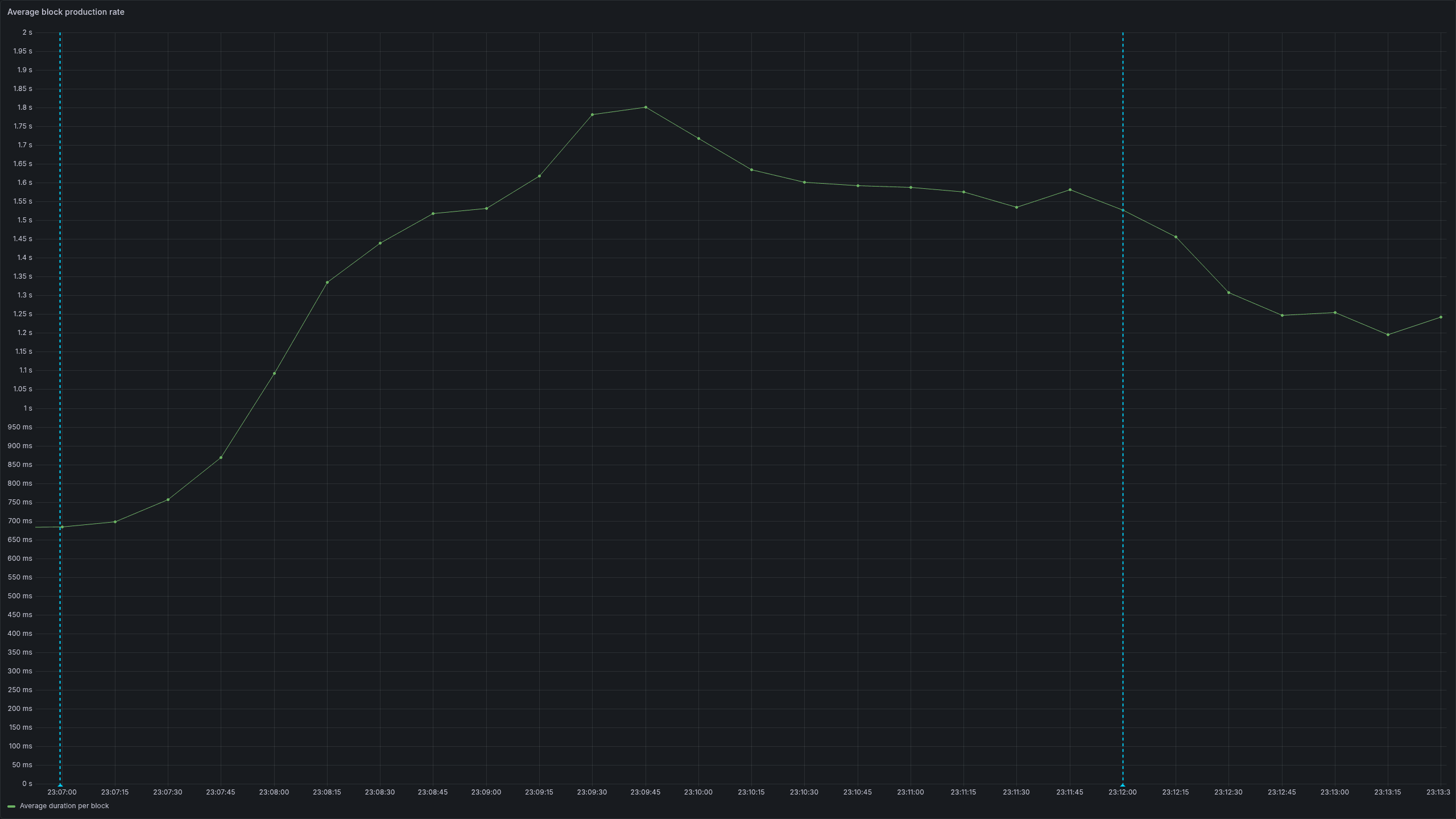
We can currently run chains consistently with 1800 tx/s and can ping much higher in shorter periods while keeping block times under 2 seconds. The above image was generated using our original test application, which includes SDK v0.53 and Comet v0.38, while the optimized application is using feature branches that will all be made available in the upcoming Cosmos stack release!
These tests are all run on production-grade networks. That means:
- Real transactions signed, verified, with gas, balance, and nonce management
- Executed on top of CometBFT with robust, distributed consensus guarantees
- P2P connections on networks between 10 and 50 nodes
- Persistent RPC requests balanced across non-validating nodes
- Reasonable infrastructure requirements (32 vCPUs, 32GB RAM)
Initial Tests
During our time building protocol-based products in Cosmos, such as the Block SDK and the Connect Oracle, we wrote some basic utilities for provisioning and testing generic Cosmos chains called Petri. It has useful abstractions and utilities for integrating with infrastructure backends such as Docker or Digital Ocean, and also for formulating the proper configs and genesis files required to start new test networks. We would plug in our chain binary, spin up a new network, and send transactions to it to get a sense of how it was performing, or run end-to-end tests.
Our first tests consisted of 5, 10, and 50 validator networks with both geo-colocation and geo-distribution across 5 data centers meant to mimic a typical enterprise network. The chain we were testing on was a standard Cosmos EVM chain with mostly default settings and stock SDK modules. We ran load tests consisting of ERC20 transfers, published at rates of 200-400 tx/s.
The initial results looked like this:
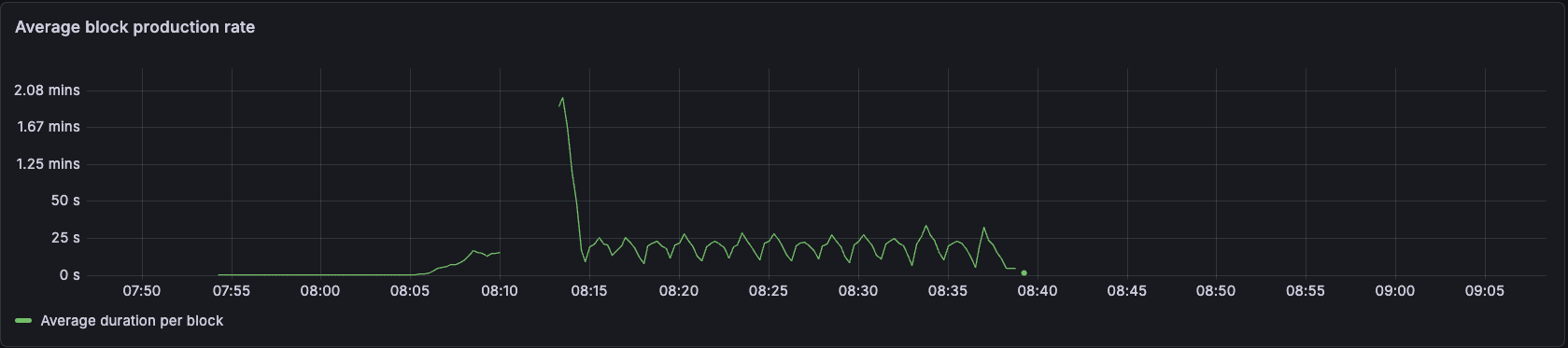
Block times grew as we could not drain the mempool efficiently.
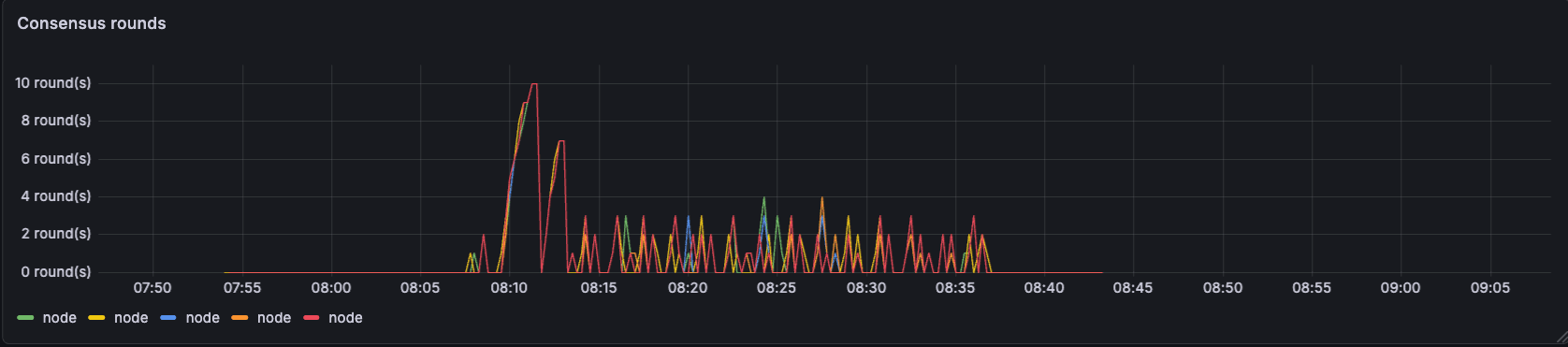
Long execution and proposal times cause consensus round increments which drive block times up.
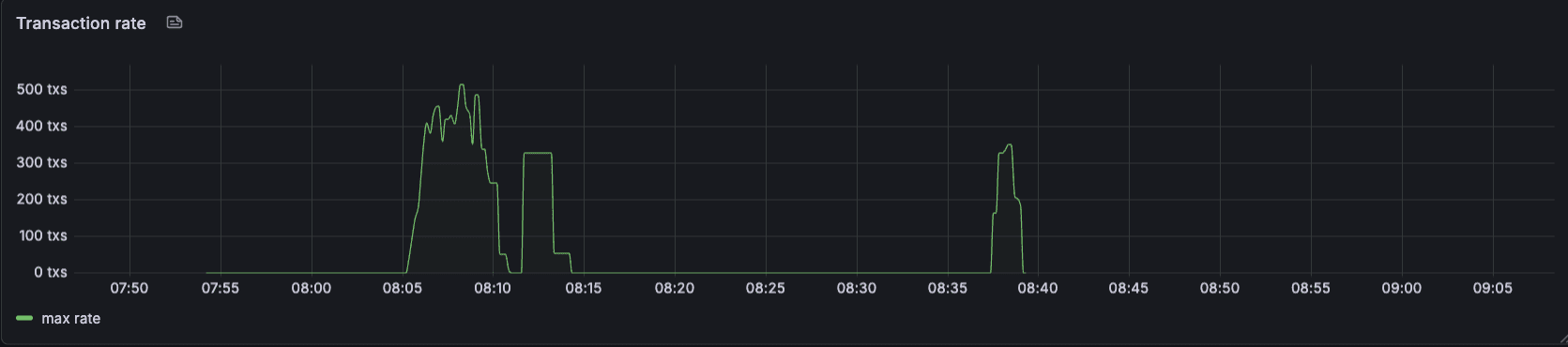
Eventually we would form a block, but our test networks were struggling under any load at all.
Eventually, we would form a block, but our test networks were struggling under any load at all.
In summary, even what we thought would be achievable in terms of transaction throughput quickly built up in the system and caused timeouts, which ground the chain’s progress to a halt. The team had many ideas about changes they wanted to test. Some of them were small parameter changes in mempool capacity or max block gas, and others were larger in scope, which reached into refactoring the CometBFT Reactor system.
The fact that each of these tests took about 20-30 minutes to set up and run, just to get roughly 5-10 minutes of data, was becoming a blocker for scaling the team’s effectiveness and output. We lacked a shared knowledge base where we could build up load test scenarios and iterate on different proof-of-concept-level ideas simultaneously in order to compare results across test runs and patches.
Test Infrastructure
To solve these problems, we built Ironbird.
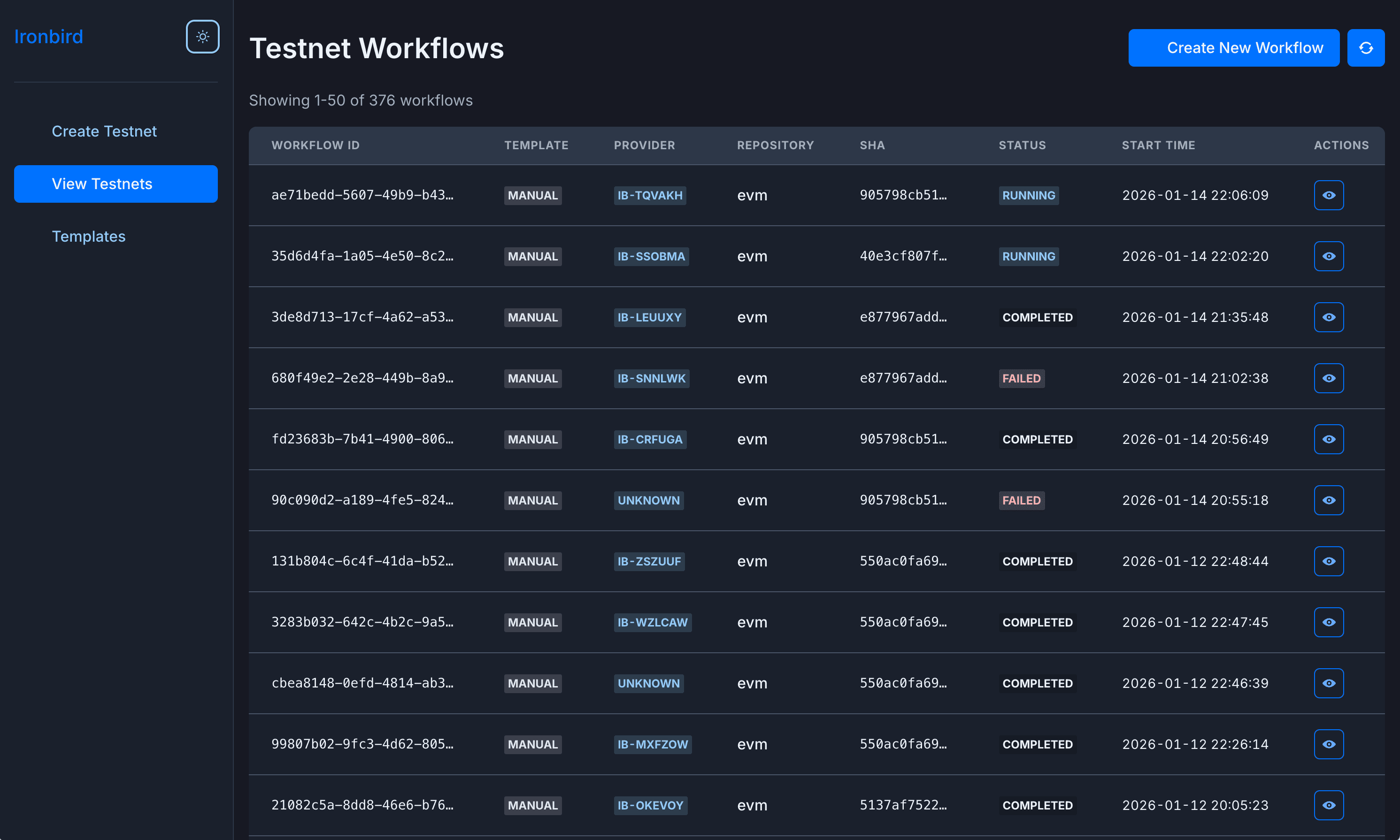
IronBird automates test network creation, instrumentation, and persistence.
Out of the box, Ironbird orchestrates the creation of the infrastructure backing our test chains and the lifecycle of those chains. It does everything from rebuilding the chain binary container using custom git commits, to providing p2p connection configuration, to funding testing accounts in the chain genesis, to terminating the infrastructure when the load tests are done.
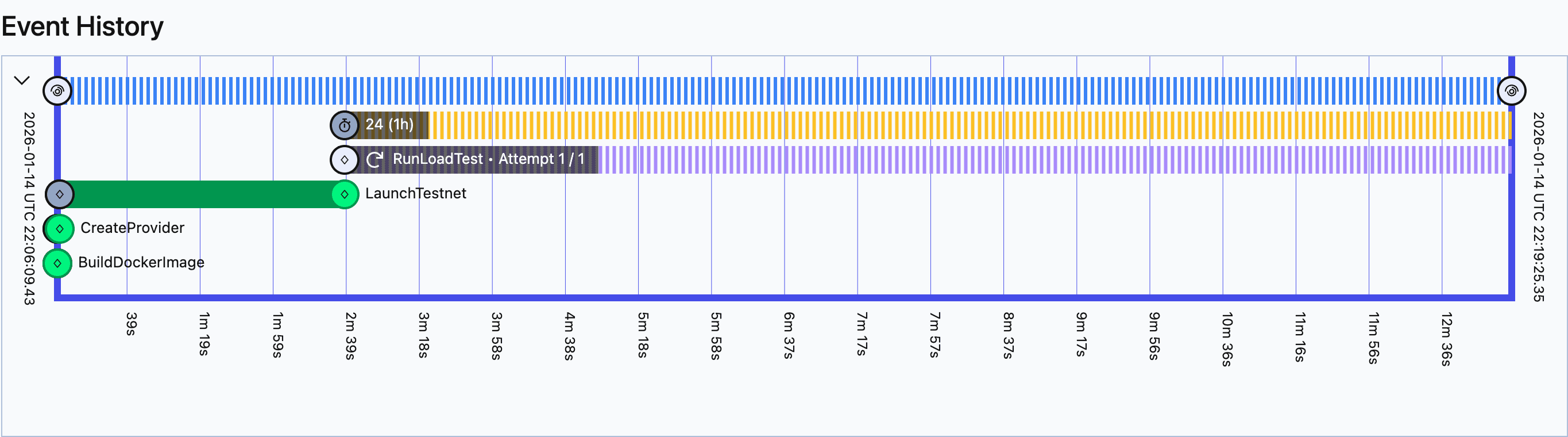
It also manages Catalyst, our load testing tool, which contains configurations for constructing different traffic patterns and transactions to execute on test networks. All of this has telemetry data scraped and put into our Grafana, logging data through Loki, profiling through Pyroscope, and we’re working on integrating tracing through Tempo. All of these tools give us a view of how Cosmos networks perform under repeatable circumstances. That allows us to define scenarios that exercise real-world behavior and iterate on how the Cosmos stack operates under those scenarios.
Iterations
Using our new infrastructure, we started to tackle the problems that showed up during our tests. We were initially constructing networks purely using validating nodes, which handled all of the transaction broadcasts as well as the RPC calls required to formulate correct transaction data. Our transaction graphs see-sawed up and down like this:
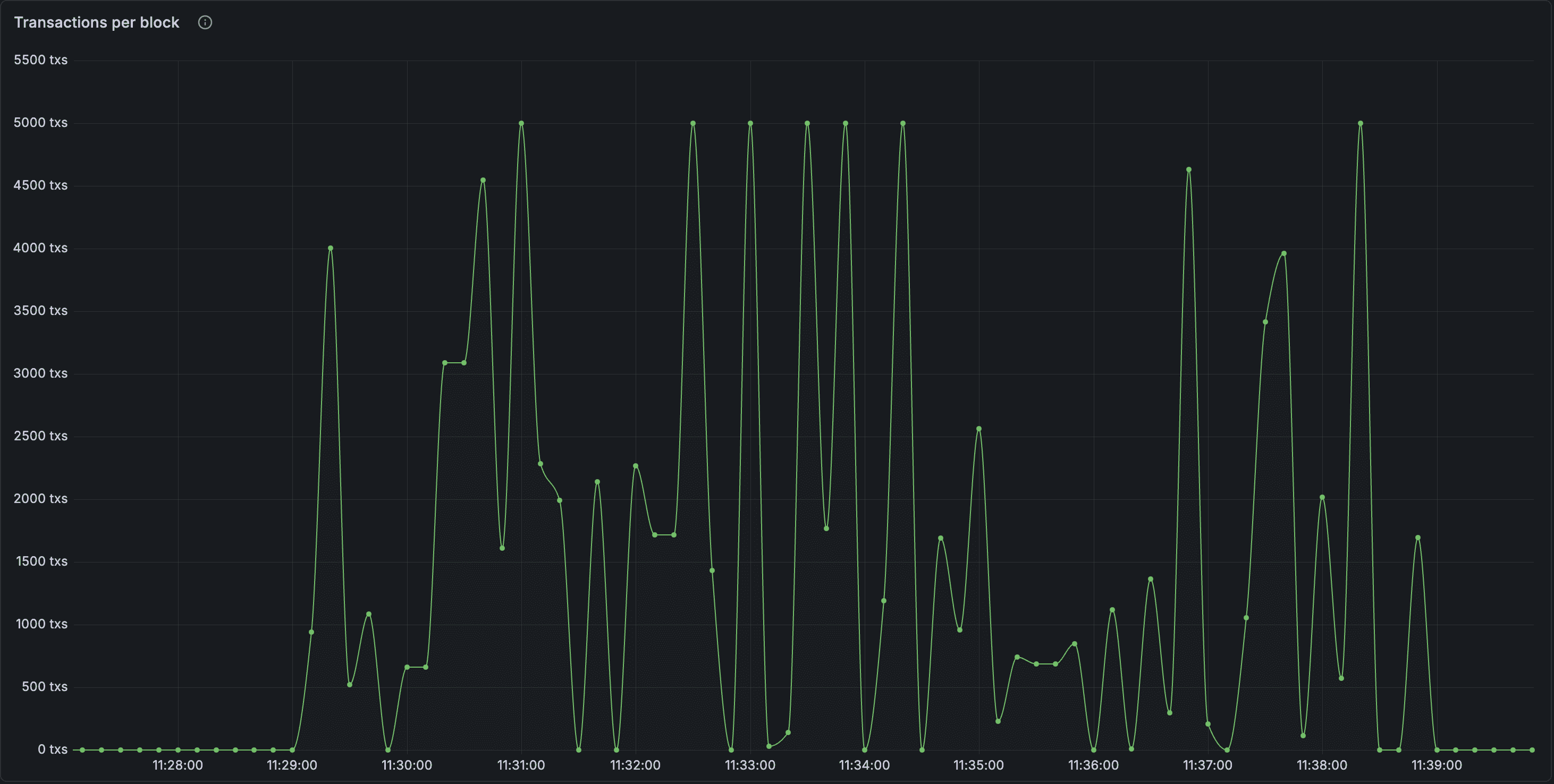
When we started to get a consistent number of transactions in blocks, we ran into another problem. As soon as transactions started accumulating in the mempool, our chain went from a baseline block time of around 2.5 seconds to over 6 seconds to process a few thousand transactions. Our block times increased exponentially with the number of transactions we were able to get into blocks.
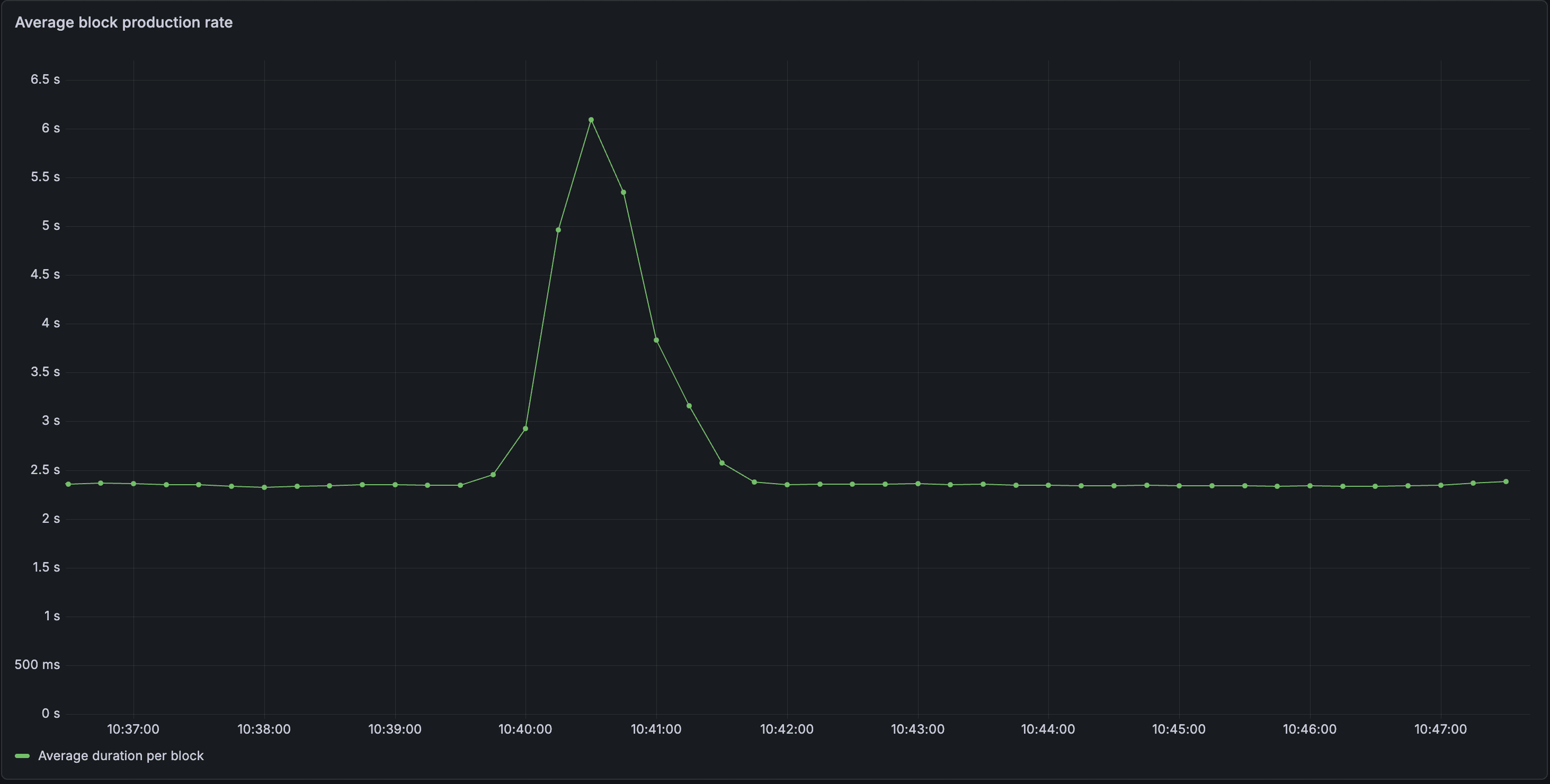
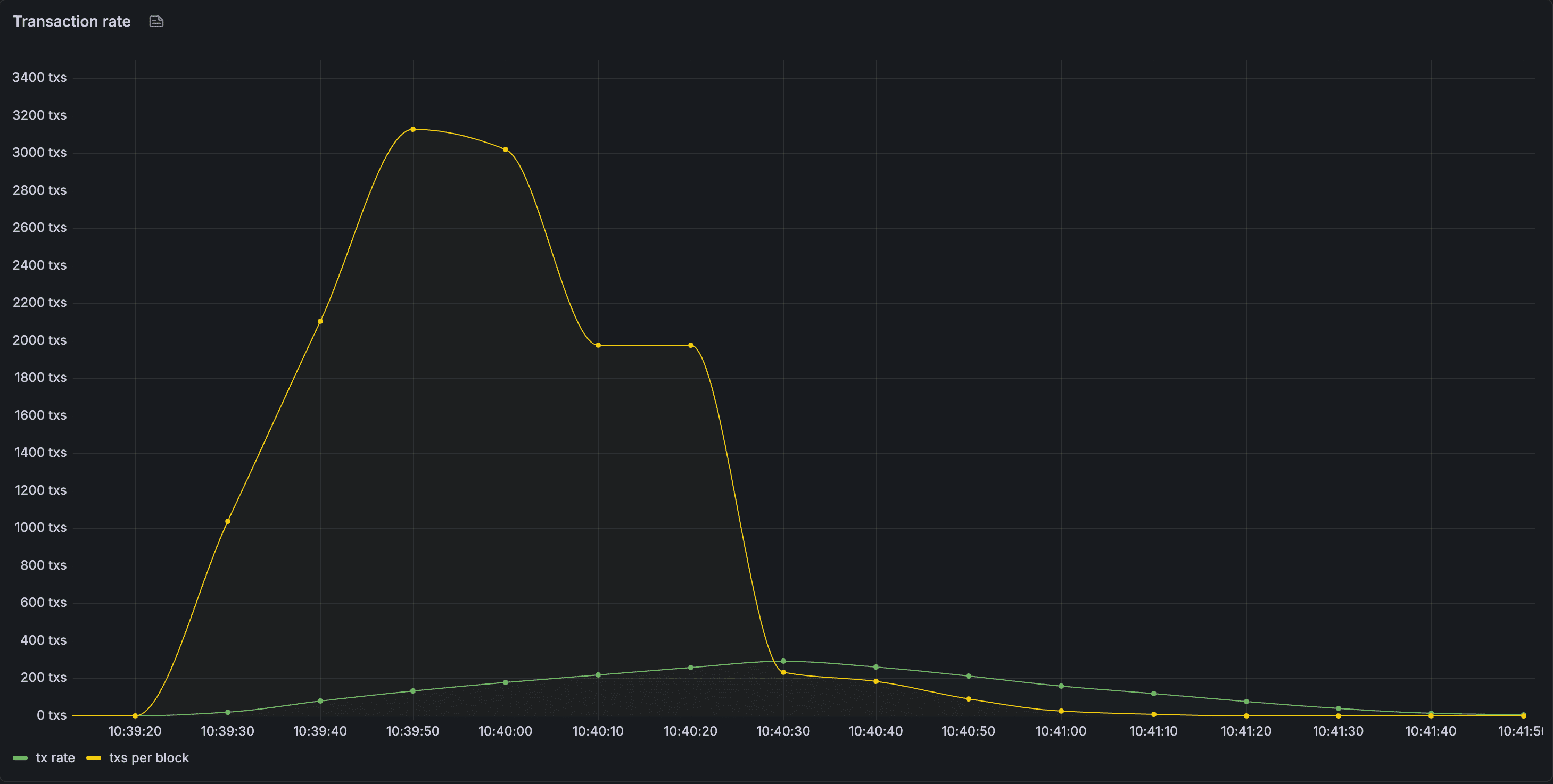
We had a major problem to solve in order to increase the throughput of our consensus and execution engines, but also to stabilize block times under load. We eventually modified our networks to look closer to production systems, where RPC nodes handle queries and ingress transactions to the network via p2p, but these tests showed a large buildup of pending messages in the p2p message queue, which were waiting to be broadcast. If we loosened the limits on the p2p throughput at all, it would effectively DOS our network via p2p storm, but if we kept these same limits, our network would no longer function.

Our p2p layer could not adequately process enough messages in order to handle gossip of hundreds of transactions on a relatively small network.
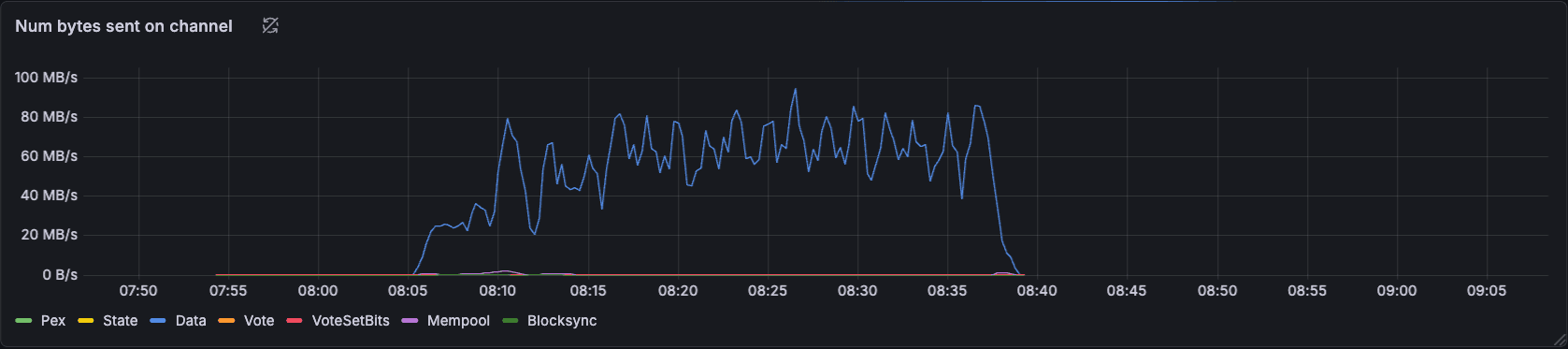
Our nodes were sending reasonable amounts of data, but the network throughput wasn’t being utilized efficiently.
In order to limit the impact of transaction gossip, we imposed limits on the number of peers to which transaction gossip would be broadcast. This provided a temporary solution, which helped us unblock usage of higher transaction rates in our load test scenarios.
Over the following months, we continued this process of iteration, identifying issues and testing out changes to reduce the impact of the largest performance bottlenecks. We’re currently running load tests using 2,000 tx/s, which produce consistent throughput of around 1,500 tx/s with some spikes higher.
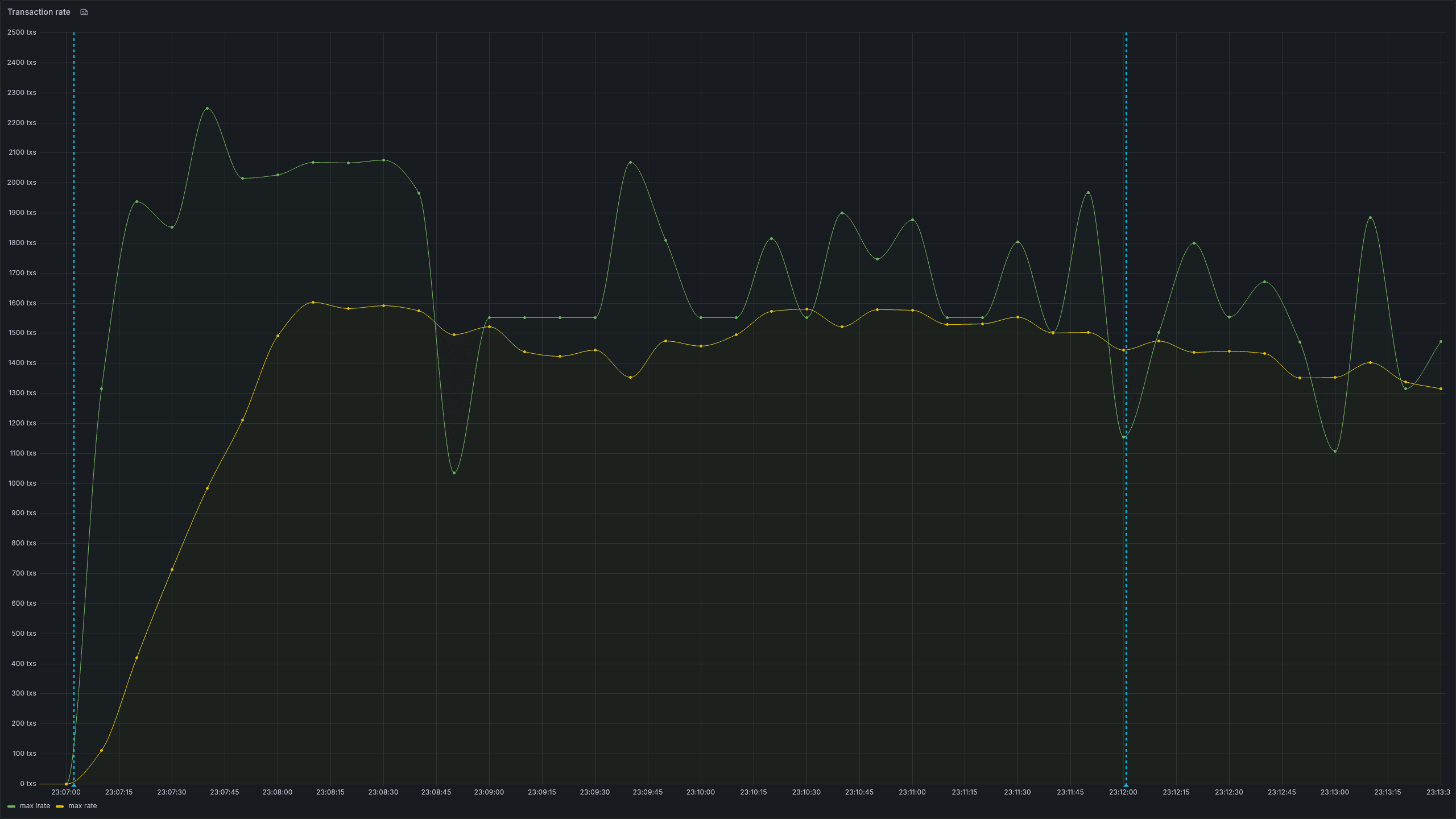
Conclusion
Since these early tests, we’ve come a long way in understanding the key bottlenecks in the Cosmos stack and have progressed numerous experimental features towards the upcoming release in order to address these. Our investments in testing infrastructure have been an important tool that we’ve used to diagnose problems and rapidly iterate on solutions.
The workloads we’ve settled on for optimization consist of either ERC20 or gas token sends. Our load testing tool has modes for pre-generating test workloads, in which the entire set of transactions is created and signed before periodically sending out batches of transactions, and a mode for persistent execution in which balances and nonces are queried and put into transactions in real time.
Both of those test setups spread transactions and queries evenly across a set of RPC nodes (non-validating nodes), which are directly connected to the core set of validators. Our test chains consist of constrained validator sets, generally 5 to 10 validators each with an equal stake.
In order to evaluate our EVM mempool performance, we vary the number of test wallets used from a couple of thousand to hundreds of thousands. By increasing this number, we reduce the frequency of nonce gaps seen in the mempool, and by keeping it low, we can ensure that pending transaction logic keeps the time to block inclusion low.
Our Stack
In the next blog posts, we’ll outline the major features we’ve built, the ones we’ve forked from other projects and are now committed to maintaining under the Cosmos umbrella, and some of the surprising and interesting quirks of Cosmos that we’ve found. We’ll address each part of the anatomy of a Cosmos node, its baseline performance, and the features we’re working on to improve performance across the board.
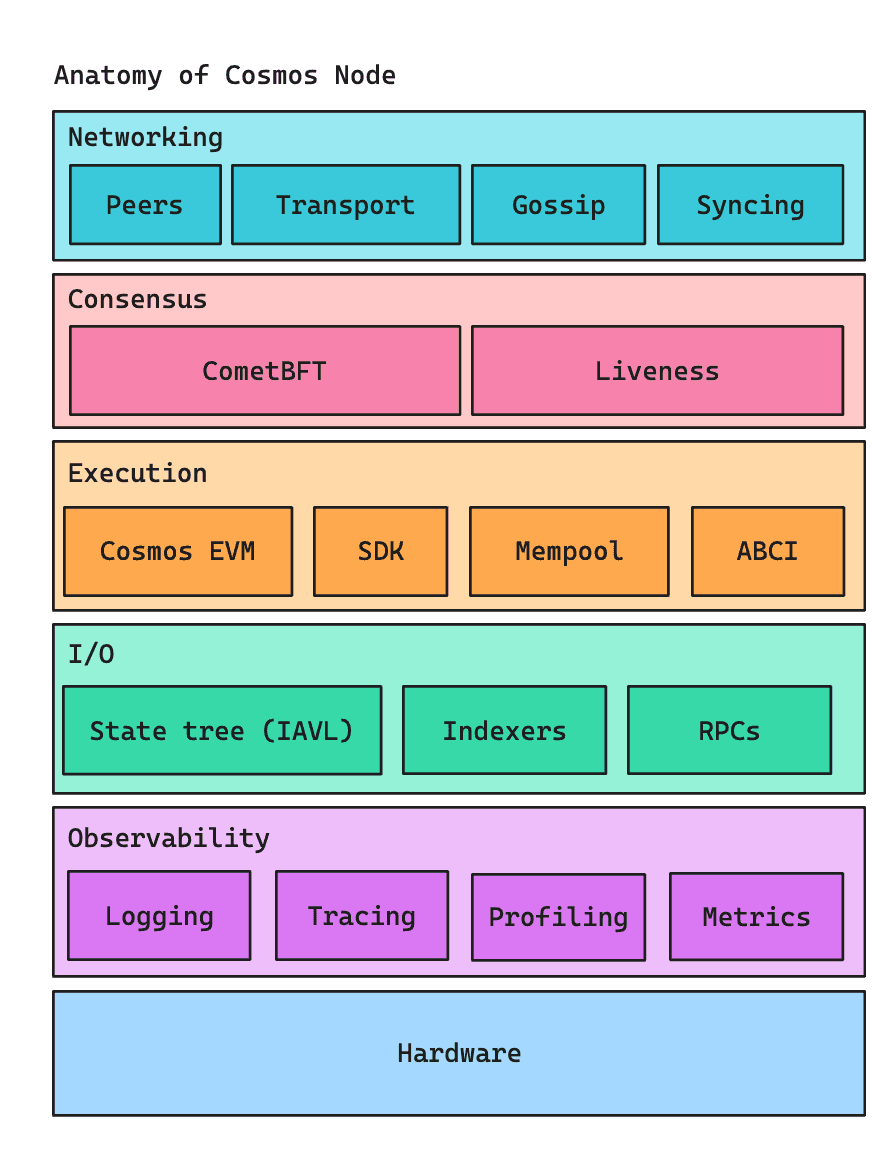
Here is a preview of some of the topics we’re excited to share more about in the future!
- How we’ve rebuilt the peer-to-peer networking stack on top of libp2p in order to remove high tail latencies seen when executing messages in parallel within CometBFT.
- Integrating BlockSTM, originally conceived by the Aptos team and written by the Cronos developers, and how parallel execution of transactions relieved time pressure in block execution and finalization.
- A deep dive into the existing IAVL store, the backing state tree within Cosmos. How the work done in other projects, such as IAVL v2 and MemIAVL, inspired a rewrite, which we’re calling IAVLx, and comparisons in read and write speed at different tree sizes.
- Debugging lock contention within the ABCI client has led us to add new methods to ABCI and a complete overhaul of the EVM mempool to enable high-throughput transaction processing in the execution client while still using the consensus client for p2p messaging.
- A modernization of the telemetry and logging utilities within the SDK, which drives data collection via Open Telemetry collectors.
Get Involved
We’re forming an open source working group around performance in Cosmos blockchains, including some of the leading teams in the space. Please reach out below to join, and pay attention to the Cosmos blog for more updates!
Join the Performance Working Group